Documentation¶
Introduction¶
What is ONNX?¶
If you don’t know about onnx you might want to read about it before since its the building block of this project. They have a nice website and great repositories with a lot of documentation to read about. Everything is open source, and really big companies in the industry are behind it (AMD, ARM, AWS, Nvidia, IBM) just to name a few. Here you can find a mix of official and non official related repositories:
- https://github.com/onnx/onnx
- https://github.com/onnx/onnx-r
- https://github.com/onnx/models
- https://github.com/owulveryck/onnx-go
- https://github.com/microsoft/onnxruntime
In short, onnx provides a Open Neural Network Exchange format. This format, describes a huge set of operators, that can be mixed to create every type of machine learning model that you ever heard of, from a simple neural network to complex deep convolutional networks. Some examples of operators are: matrix multiplications, convolutions, adding, maxpool, sin, cosine. They provide a standardised set of operators here. So we can say that onnx provides a layer of abstraction to ML models, which makes all frameworks compatible between them. Exporters are provided for a huge variety of frameworks (PyTorch, TensorFlow, Keras, Scikit-Learn) so if you want to convert a model from Keras to TensorFlow, you just have to use Keras exporter to export Keras->ONNX and then use the importer to import ONNX-TensorFlow.
In the following image, you can find an example on how a onnx model looks like. Its just a bunch of nodes that are connected between them to form a graph. Each node has an operator that takes some inputs with some specific dimensions and some attributes and calculates some outputs. This is how the inference is calculated, just forward propagating the input along every node until the last one is reached.
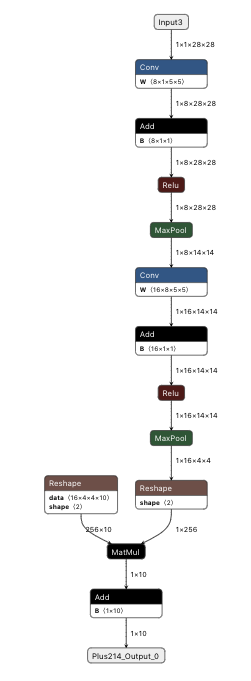 mnist
mnist
So this .onnx format can describe machine learning models through a set of nodes that contain specific operators connected among them. On top of that, they also offer a set of the so called “runtimes” see link. A runtime allows to run inference on a model, and they offer different ones in a wide variety of languages and hardware. Unfortunately, all the runtimes rely on modern versions of C/C++ with many abstractions and dependancies, which might be a no go for some specific projects. Here is where we come in.
What is cONNXr¶
Well, now that you know about onnx, our project is just a runtime that runs inference on onnx models. The c means that is implemented in C language and the r means that its a runtime for ONNX. The only difference between this runtime and the others, is that this one is written in pure C99 without any dependancy. This means that it should be able to compile with almost any compiler, no matter how old it is. Our goal is to enable embedded devices that doesn’t have much resources or fancy features (like GPUs or any type of hardware accelerator) to run inference. No GPUs, no multithreading, no dependancies, just pure C code with the lowest possible footprint. Train your model in whatever ML framework you want, export it to .onnx and deploy it wherever you want.
You might also find this project useful if you work with some bare metal hardware with dedicated accelerators. If this is the case, you might find useful to reuse the architecture and replace the specific operators (functions) by your own ones.
Or perhaps you have a different use case. If this is the case, we would love to hear about it.
File structure¶
The most relevant files and folders are the following ones:
include/src: Source and header C files.include/operators/onnx/: Autogenerated header files for all operators and versions. There is one header file per operator, and within each file there is one function declaration for each data type. For example, for the operatorconvversion 11 there is one header file, that contains 3 function declarations (double, float and float16). Note that these functions are defined as extern and not implemented.src/operators/implementation: Here is where all the operators implementations are located. The functions that are defined here must use the prototype defined ininclude/operators/onnxmentioned above. See some examples.src/operators/resolve: This is autogenerated code, that resolves the mapping between an operator + data type and the function that should be executed.src/operators/operator_set.c: Autogenerated file that stores the relationship between an operator name (i.e.Conv) and the function that resolves its data type. Operator version is also taken into account.scripts/onnx_generator: Set of Python scripts that generates the header and C files existing ininclude/operators/onnx,src/operators/resolveandsrc/operators/operator_set.c.src/testandinclude/test: Test code divided into two levels: operator level and model level.test: Test vectors on operator and model level. Bunch of.onnxmodels and.pbfiles (input + expected output)
Operators interface¶
All ONNX operators comply with the following interface. This struct contains all the data that an operator needs to run, like its inputs and attributes. In operator_executer it contains the pointer to the function that runs that specific node. For example, if node i contains a Conv, that operator_executer will point to the conv function defined in src/operators/implementation.
You can check more information about Onnx__NodeProto and Onnx__TensorProto structs in onnx.pb-c.h, which is a file that is generated from the ONNX common interface.
struct node_context{
Onnx__NodeProto *onnx_node;
Onnx__TensorProto **inputs;
Onnx__TensorProto **outputs;
operator_executer resolved_op;
};
Types and Structures¶
We can divide the types and structures that this repo uses into two:
- ONNX structures: These structures are exactly (or almost) the same as the ones that ONNX defines in its onnx.proto. See
onnx.pb-c.h. We list the most relevant ones below. - Custom structures: These structures are defined ad hoc for this project.
ONNX structures¶
Onnx__GraphProto¶
Defines the graph of a model, made of different nodes Onnx__NodeProto. See onnx.pb-c.h.
struct _Onnx__GraphProto
{
ProtobufCMessage base;
size_t n_node;
Onnx__NodeProto **node;
char *name;
size_t n_initializer;
Onnx__TensorProto **initializer;
size_t n_sparse_initializer;
Onnx__SparseTensorProto **sparse_initializer;
char *doc_string;
size_t n_input;
Onnx__ValueInfoProto **input;
size_t n_output;
Onnx__ValueInfoProto **output;
size_t n_value_info;
Onnx__ValueInfoProto **value_info;
size_t n_quantization_annotation;
Onnx__TensorAnnotation **quantization_annotation;
};
Onnx__NodeProto¶
Information for a given node (a node has inputs and attributes and provides an output using a given operator). See onnx.pb-c.h.
struct _Onnx__NodeProto
{
ProtobufCMessage base;
size_t n_input;
char **input;
size_t n_output;
char **output;
char *name;
char *op_type;
char *domain;
size_t n_attribute;
Onnx__AttributeProto **attribute;
char *doc_string;
};
Onnx__TensorProto¶
One of the most important types that you will see, is the Onnx__TensorProto. It just defines a vector, an array, a matrix, or whatever you want to call it. It is quite convinient to use, because it is quite generic. You can store different types of values, with different sizes. As an example, lets say that we want to store a 3 dimension vector. In that case n_dims=3 and dims[0], dims[1], dims[2] will store some values. Lets store some float values, so data_type=ONNX__TENSOR_PROTO__DATA_TYPE__FLOAT. In this case n_float_data=dims[0]*dims[1]*dims[2] and float_data will contain all the values in a single dimension array. The tensor has also a name.
struct _Onnx__TensorProto
{
ProtobufCMessage base;
size_t n_dims;
int64_t *dims;
protobuf_c_boolean has_data_type;
int32_t data_type;
Onnx__TensorProto__Segment *segment;
size_t n_float_data;
float *float_data;
size_t n_int32_data;
int32_t *int32_data;
size_t n_string_data;
ProtobufCBinaryData *string_data;
size_t n_int64_data;
int64_t *int64_data;
char *name;
char *doc_string;
protobuf_c_boolean has_raw_data;
ProtobufCBinaryData raw_data;
size_t n_external_data;
Onnx__StringStringEntryProto **external_data;
protobuf_c_boolean has_data_location;
Onnx__TensorProto__DataLocation data_location;
size_t n_double_data;
double *double_data;
size_t n_uint64_data;
uint64_t *uint64_data;
};
Custom structures¶
Since we are at a very early stage, structures are constantly evolving. Have a look to the code in order to know more. At some point we will also document them here.
Protocol Buffers¶
In order to convert from the ONNX interface defined in onnx.proto, the protoc library is used. onnx uses protocol buffers to serialize the models data. Note that protobuf-c is used to generate the pb/onnx.pb-c.c and pb/onnx.pb-c.h. Files are already provided, but you can generate it like this:
protoc --c_out=. onnx.proto
Autogenerated code¶
In order to avoid boilerplate code, some .c and .h files are autogenerated from Python. You can find these Python scripts and more information under scrips/onnx_generator folder. These Python scripts take into account a given ONNX version and generates all the “infrastructure” from it.
Versioning¶
ONNX is constantly evolving and new operators and versions are regularly being released. This project aims to keep up with that using the autogenerated code mentioned above.
Operators¶
All onnx operators are defined in the official doc. Our goal is to implement as many as possible, but if you have a model with a custom operator, that also fine.
All operators share a common interface. This structure is available as an input parameter to all operators, and it contains all the data you need, like the input tensors and attributes and a pointer to the output.
struct node_context{
Onnx__NodeProto *onnx_node;
Onnx__TensorProto **inputs;
Onnx__TensorProto **outputs;
operator_executer resolved_op;
};
Lets say that you want to implement the Add operator, that just adds two numbers or tensors. You can access to its inputs with the following code. Once you have that, its pretty straightforward to access the data within the tensor (see Onnx__TensorProto struct)
Onnx__TensorProto *A = searchInputByName(ctx, 0);
Onnx__TensorProto *B = searchInputByName(ctx, 1);
On the other hand you will need to store the result in a variable, so that other nodes can reuse that output. Just use the following function and populate the content.
Onnx__TensorProto *C = searchOutputByName(ctx, 0);
If the operator you are implementing has some attributes, you can also easily get them with. Just replace auto_pad by your attribute name.
Onnx__AttributeProto *auto_pad = searchAttributeNyName(
ctx->onnx_node->n_attribute,
ctx->onnx_node->attribute,
"auto_pad");
Its also important to note that each operator is usually defined for more than one data type like float, double or uint8_t. In order to address this, we have decided to define one function per data type, trying of course to share as many code as possible between different data types implementations.
Tracing¶
We utilize macros to enable fine tracing of components. Trace macros can act as asserts and therefore may abort execution if an erroneous state is detected.
If not explicitly enabled, all tracing components are stripped before compilation!
Trace prints look like this:
[MACRO LEVEL] FILE:LINE SCOPE MSG
- MACRO describes which macro produced the print
- LEVEL describes the minimum
TRACE_LEVELneeded to generate this print - FILE is the file in which the macro was called
- LINE is the line number in which the macro was called
- SCOPE is an optional block description
- MSG is the actual logged message
To enable tracing you need to specify a default TRACE_LEVEL starting from 0.
make clean all TRACE_LEVEL=0
|TRACE_LEVEL|Meaning
|————:|:——
| undefined|disable tracing
| 0|no prints, except for errors
| 1|execution flow related prints (function entry/exists, decisions)
| 2|data flow related prints (input/output meta data)
| 3+|internal state of algorithms
The TRACING_LEVEL can be overwritten at file and function granularity without recompilation.
When tracing is enabled, each macro checks the CONNXR_TRACE_FILE and CONNXR_TRACE_FUNCTION env variable for overrides.
Overrides are specified in following format:
CONNXR_TRACE_FILE=<filename>:<trace_level>{;<filename>:<trace_level>}
CONNXR_TRACE_FUNCTION=<function>:<trace_level>{;<function>:<trace_level>}
So you may execute
make clean all TRACE_LEVEL=0
CONNXR_TRACE_FUNCTION=operator__onnx__maxpool__12__T_tensor_float:3 make test_operators
to only generate a detailed trace for a specific operator (maxpool in this case).